
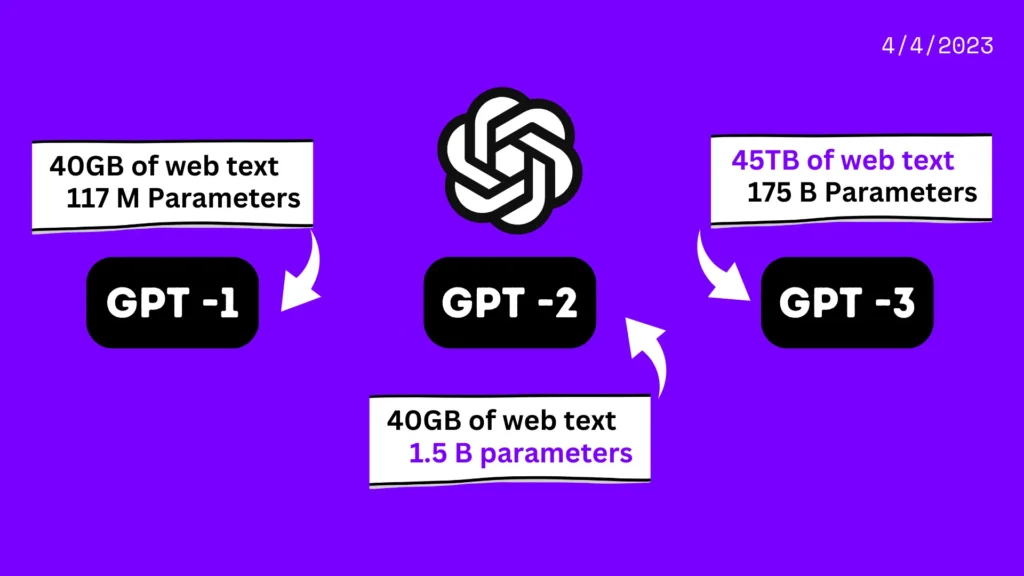
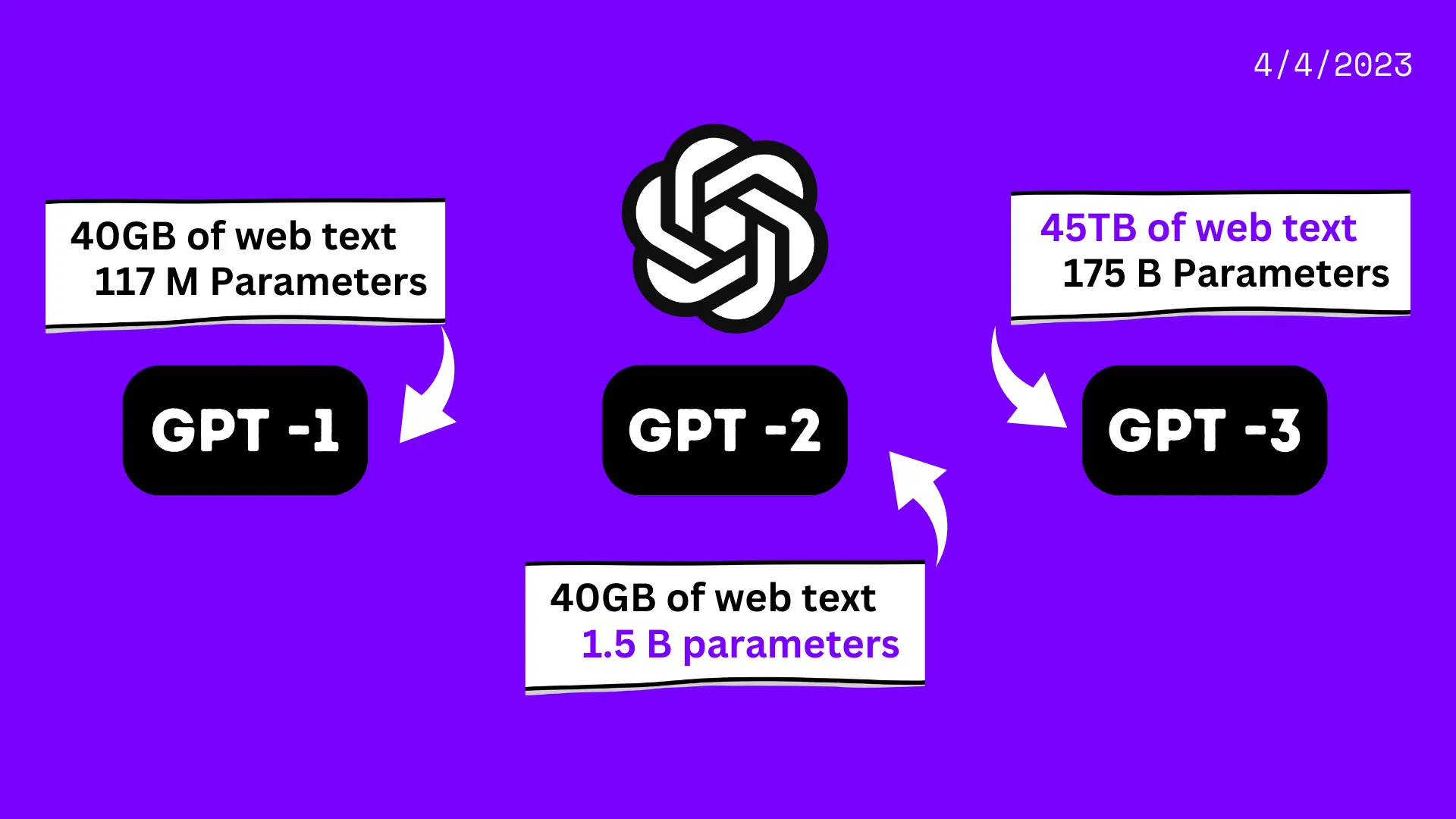
The GPT language model (Generative Pre-trained Transformer) is a type of artificial intelligence that can generate human-like text in response to a given prompt. OpenAI first introduced it in 2018 and has since gone through several iterations and updates, the most recent being GPT-3. The original GPT model, released in 2018, had 117 million parameters. It was trained on a dataset of 40GB of web text.
GPT-3 can generate brief phrases, articles, poems, and even computer code. Its ability to perceive context and synthesize sophisticated text has led to several natural language processing advances. GPT-3 can accomplish linguistic tasks without training. Therefore, the model can respond to cues with text without being taught. This has enabled chatbots, content generation, and even new programming languages.
It has become one of the most powerful tool ever invented. Some people even compared it with the like of ground breaking inventions like Steam Engine, Printing press and Dynamo. There around 6 years of history lies in it. Let’s take a look at its history.


![Sora Open AI: The AI Video Generating Tool [Explained]](https://curioussteve.com/storage/2024/03/Open-AI-Sora-Explained-120x86.webp)

CHAT GPT: Verison History
GPT 1 (2018):
The original chat GPT was inroduced in 2018 by Open AI. It was created to generate human-like text in response to a given prompt. The model was trained on a dataset of 40GB of web text, using a transformer-based architecture. The first GPT model contained 117 million parameters and could write logical, grammatical language. It could not recognize context or generate longer, more sophisticated paragraphs.
The GPT paradigm pioneered transformer-based design. This architecture processes sequential data like language by considering context and dependencies. This attention mechanism helps the model recognize word-phrase associations and generate more coherent and contextually relevant content in response to a prompt.
Unsupervised learning is another key GPT model feature. GPT models are pre-trained on massive amounts of unlabeled text input, unlike typical machine learning techniques.
GPT 2 (2019):
The next model, GPT 2 was released in 2019 by Open AI. It served as an extension to the original Chat GPT. It is is designed to generate more sophisticated and realistic text in response to a given prompt. The GPT-2 model was trained on almost 40GB of text, much more than the first GPT model. It generates lengthier, more cohesive texts with 1.5 billion parameters, ten times the original GPT model. The second verison of Chat GPT used a multi-layer transformer architecture. It allows the model consider different levels of abstraction in the input text and provide more complicated and nuanced replies.
Unlike, GPT-1, GPT-2 can translate, answer questions, and summarize. Due to the increased controversies around it, the model wasn released in a limited form. In addition to that, OpenAI provided access to a smaller version of the model that is less capable of generating fake text.
GPT 3 (2020):
Chat GPT 3 is the latest and most powerful iteration of the GPT series of language models. It has over 175 billion parameters, making it the largest and most complex language model ever created. A total of 45-terabyte text dataset trained it. Its responses are based on data and knowledge up to September 2021.
This version saw the most creative yet nuanced replies form Chat GPT. Therefore, OpenAI has limited access to the full GPT-3 model. It even implemented a range of safety protocols to prevent its misuse. Thi version has become a valuable tool for researchers, developers, and businesses working in the field of NLP.
 How Chat GPT Works?
How Chat GPT Works?
Chat GPT training is based on a deep learning algorithm called a transformer model. It allows for CHAT GPT to generate content that is logical, free of grammatical errors, and significant on a semantic level. Chat GPT analyzes your query or prompt and generates a response. This method entails separating the input into words and phrases, understanding their context, and then providing an acceptable response.
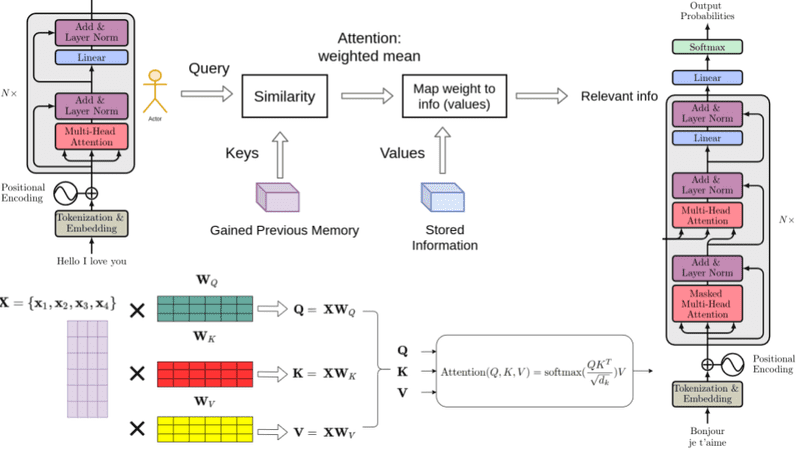 What is tranformer model? Chat GPT Working Mechanism
What is tranformer model? Chat GPT Working Mechanism
The transformer model is a type of neural network architecture that is used in language processing tasks such as natural language understanding and generation. Vaswani et al. introduced it in 2017 and it has become a mainstream language modeling method.
An embedding layer embeds the input token sequence (words or subwords) into a high-dimensional space in the transformer architecture. Encoder and decoder layers process the embedded sequence.
The transformer model encoder layer uses a multi-head self-attention mechanism to rank each word in the input sequence. A feedforward neural network generates encoder output from the self-attention mechanism output. Multi-head self-attention and an attention mechanism allow the transformer model’s decoder layer to attend to the encoder’s output. The final output sequence is produced by passing the decoder’s output through a feedforward neural network.
The GPT (Generative Pre-trained Transformer) architecture trains the model unsupervised on a vast corpus of text. The model learns to anticipate the future word based on prior words during training. This pre-training gives the model a general comprehension of language that may be refined for specific language tasks like question-answering or summarization.
In laymen terms, it constantly learns and update the knowledge base based on the text that we enter. In other words, it always improving and evolving.
Aitechnologies-it/gpt-mini: Make Your Own Chat GPT
If you are into experimenting or developing your own GPT model, this model hosted on Github repository will surely helps you. This repository contains a simplified Tensorflow (re-)implementation of the OpenAI GPT inspired by Karpathy’s minGPT Pytorch implementation.

For more interesting news and reveals related to tech, follow us on our telegram channel. We haunt interesting news every day on the Internet.


![Sora Open AI: The AI Video Generating Tool [Explained]](https://curioussteve.com/storage/2024/03/Open-AI-Sora-Explained-350x250.webp)

![Sketch.metademolab: Bring children’s drawings to life [Explained]](https://curioussteve.com/storage/2023/08/Sketch.metademolab-350x250.webp)

{kind=link}
Discussion about this post