
Sora OpenAI: OpenAI continues to push the boundaries of artificial intelligence with its latest creation, Sora. They recently launched their homepage. This tool is the next big thing after Open AI’s successful GPT-3 model, Dall.E., and other innovative AI projects. So what is Sora? Let’s find out together!
What is Sora?
For starters, Sora is a text-to-video model designed to comprehend and simulate the physical world in motion. In other words, this tool can generate videos from a prompt using AI. It is a groundbreaking model that can generate videos up to a minute in length while maintaining exceptional visual quality and adherence to user prompts. In the field of AI, this new idea is a big step forward because it bridges the gap between text input and active, lifelike video output.
This groundbreaking technology has the potential to revolutionize industries such as film production, virtual reality, and even education. By allowing users to create realistic videos without the need for expensive equipment or extensive training, Sora represents a major leap forward in AI capabilities. So how does it works?



![Sketch.metademolab: Bring children’s drawings to life [Explained]](https://curioussteve.com/storage/2023/08/Sketch.metademolab-120x86.webp)
Language Understanding: A Hurdle That Open AI Already Masters
Before generating videos, a model like Sora should have the ability to understand prompts. Open AI has successfully tackled the challenge of language understanding by developing advanced models like GPT-3. These models are trained to comprehend and generate human-like text based on prompts given to them.
One of Sora’s standout features is its deep understanding of language. This proficiency enables the model to accurately interpret prompts, generating characters that express vibrant emotions and scenes that align with the user’s textual input. The fusion of language understanding and visual representation results in compelling, contextually rich videos. Check out this video that it has generated.
Since Sora is directly related to Open AI’s line of projects, it has already overcome the hurdle of understanding human language and emotions. The next big step is to generate a video that can accurately reflect these understandings in a realistic and engaging way. Let’s see how Sora has did that.
How Does Sora Work?
Sora is a cutting edge AI innovation that can easily turn text prompts into videos. Behind the scenes, Sora leverages sophisticated architecture and advanced techniques to bring this magic to life. At its core, Sora utilizes a transformer architecture, a key component in many cutting-edge AI models. This architecture excels at handling complex relationships within data, allowing Sora to understand and generate coherent sequences of visual information.
Sora builds on the recaptioning method from DALL·E 3, generating highly descriptive captions for visual training data. This method enhances the model’s ability to interpret text directions accurately, ensuring a faithful translation of prompts into dynamic visual sequences.
At its core, Sora operates as a diffusion model, a unique approach to generating videos. It starts with a video that looks like static noise and improves it step by step, getting rid of the noise to show a smooth, moving sequence. This step-by-step change makes sure that the generated material matches what the user asked for. Sora is trained on a diverse range of visual data, it represents videos and images as collections of smaller units known as patches. This approach unifies the representation of data, treating patches akin to tokens in GPT models. The result is a versatile model capable of handling various durations, resolutions, and aspect ratios.
Sora: How Diffusion Model Works?
Diffusion models are inspired by the process of diffusion, which describes the spreading of particles from a dense space to a less dense space. Imagine you have a drop of blue food coloring, and you drop it into a clear glass of water. Before it hits the water, all the blue molecules are squeezed into a tiny droplet. When the droplet touches the water, those blue molecules start spreading out, slowly turning the entire water blue. It’s like watching the color move from a concentrated spot to fill the entire space. This idea of particles spreading out is what inspires diffusion models, where information or changes gradually spread through a system.
Just like dropping food coloring into water, images can be transformed in a similar way. Imagine your picture pixels spreading out and getting mixed up, turning the image into random noise. Diffusion models learn by first transforming images into this chaotic state and then figuring out how to bring them back to their original form. It’s like a creative way for the AI to teach itself how to unscramble images. Diffusion models have become a popular choice for use as image generators like GAN(Generative Adversarial Networks). DALL.E works on the same principle.
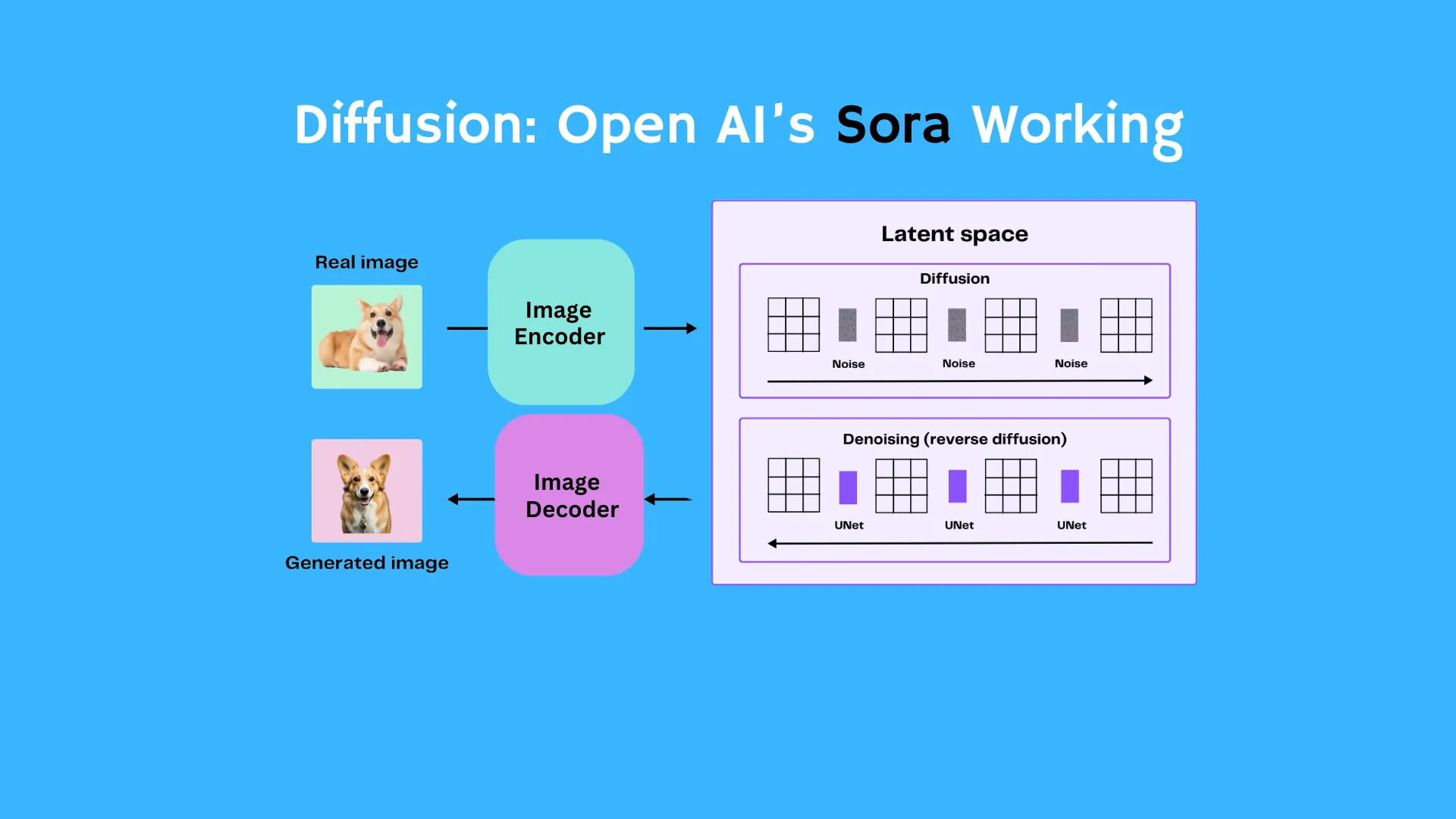
Sora OpenAI: Step By Step Working Process
Here’s a step by step process of how things are generated by using diffusion process.
- Text Encoding:
- The textual prompt is fed into a text encoder. The text encoder transforms the prompt into a numerical representation, often a vector in a high-dimensional space.
- Next, this vector captures the semantic meaning of the prompt.
- Diffusion Process:
- After that, the encoded vector undergoes a process of diffusion.
- During diffusion, a noisy version of the image is generated based on the representations learned during the training phase.
- Denoising:
- The model initiates the denoising process, which it learned during training.
- Step by step, the model progressively removes the noise from the vector.
- Clean Vector:
- The result is a denoised vector that represents the original intent of the prompt without the added noise.
- Image Decoding:
- The denoised vector is then passed to the image decoder.
- The image decoder converts the clean vector, composed of numerical values, back into an image.
- Final Output:
- The image generated by the decoder serves as the final output from the model.
- This output visually represents the transformed and denoised version of the original prompt.
Real-World Simulation: The Challenge OpenAI is Currently Working on
While Sora boasts impressive capabilities, Open AI acknowledges certain weaknesses. Real-world simulation is one such challenge that Sora will need to overcome in order to reach its full potential. Challenges may arise in accurately simulating the physics of complex scenes or understanding specific cause-and-effect instances.
For instance, if we provide a prompt for Sora to generate a video of a melting ice cream cone. The user might describe a scene where an ice cream cone is exposed to sunlight, causing the ice cream to gradually melt.
The challenge comes in ensuring that the model accurately simulates the melting process. Sora might struggle to show the realistic transformation of the ice cream as it melts, including the dripping and changes in shape. As a result, the generated video might not fully capture the intricate details of the melting event, possibly leading to a less accurate or faithful picture of the user’s prompt.
Sora OpenAI: How to Access Sora
If you want to try Sora like Chat GPT, you have to wait for sometime. According to Open AI, Sora is Currently accessible to red teamers for risk assessment and a select group of visual artists, designers, and filmmakers for valuable feedback. OpenAI is taking an inclusive approach by involving external collaborators to enhance the model’s capabilities. This early sharing of research progress aims to engage the wider community, providing a glimpse into the future of AI capabilities.
While specifics about Sora’s broader public availability are yet to be disclosed, OpenAI is prioritizing safety by involving policymakers, educators, and artists worldwide to understand concerns and identify positive use cases. As OpenAI continues its commitment to responsible AI development, users are encouraged to stay updated on developments through their Twitter and official website. For more details, visit



![Sketch.metademolab: Bring children’s drawings to life [Explained]](https://curioussteve.com/storage/2023/08/Sketch.metademolab-350x250.webp)


{kind=link}
Discussion about this post