Apple Personal Voice: Apple has shown its commitment to innovation over and over again by releasing new technologies that change the way we use products. Apple has always been on the cutting edge of technology. With the iPhone, they invented the modern smartphone, and with the iPad, they changed the tablet market. The company’s attention to detail, skill at design, and ability to seamlessly combine hardware and software have always pushed the limits of what is possible in consumer devices. For instance, Apple has also made changes in software, such as the App Store ecosystem, which has changed how we access and use software programs.
The launch of Face ID is one famous example of Apple’s innovation. Face recognition was first used in the iPhone X to unlock devices and authorize payments securely and easily. Above all, this cutting-edge feature used complex hardware components and machine learning techniques to accurately map and recognize unique facial features. Face ID demonstrated Apple’s ability to integrate hardware innovation, software optimization to provide a smooth and secure user experience. In conclusion, this example demonstrates how Apple’s drive to pushing technology boundaries has reshaped sectors and established new customer expectations.
Now Apple is doing the same with a new ground-breaking feature called “Personal Voice”
What is Personal Voice?
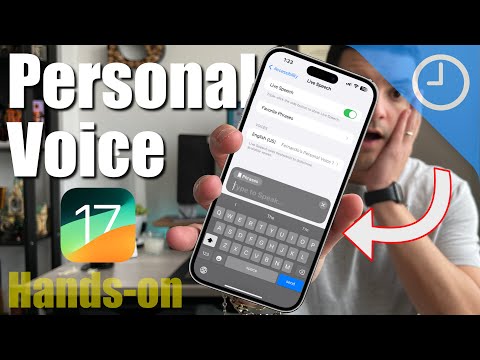
Personal voice is a cool new feature that is announced by Apple for their latest iOS 17 release. This feature works on the basis of AI. This feature can generate a digital voice version of yours based upon the training you provided to the software. Apple’s iOS 17 “Personal Voice” feature illustrates its commitment to leveraging cutting-edge technologies to give users more power. This cutting-edge function utilizes AI to let users make their own unique digital speech representation. Individuals can produce a very lifelike and natural-sounding digital representation of themselves by training the software with their own voice.
This breakthrough could improve accessibility for speech-impaired people and offer up new content creation options like audiobooks and podcasts. Apple’s implementation of the “Personal Voice” feature underscores the company’s ability to merge AI advancements with user-centric innovation, further cementing their reputation as pioneers in the tech industry.
How Personal Voice Works?
Apple’s iOS 17 “Personal Voice” feature relies on advanced machine learning techniques to produce digital speech representations of people. The inner workings involve two main stages:
- Training
- Synthesis.
Training:
During the training phase, users are prompted to provide a substantial amount of audio recordings in their natural voice. These recordings are used to train the AI model to recognize the distinctive properties of the user’s voice, such as pitch, tone, cadence, and pronunciation patterns. The AI system extracts and encodes these information into a mathematical representation using neural networks and deep learning methods, resulting in a speech “print” or model.
In the case of Apple iOS 17, users need to record over 150 random phrases with their own voice. This would take around 20-25 minutes to do that.
Synthesis:
Then comes synthesis. In the synthesis phase, the AI combines the learned voice model with text-to-speech (TTS) linguistic patterns. The model analyzes linguistic content and mimics the user’s voice using learned vocal nuances. This method entails intricate adjustments to pitch, intonation, and tempo to match the user’s speech. This can be utilized to build a TTS system that generates voice from text input.
![Apple Personal Voice [Explained]](https://curioussteve.com/storage/2023/08/Apple-Personal-Voice-Explained.webp)